| 5 The Cego SQL language |
|---|
| Back to TOC |
The Cego SQL query language enables the database user to perform any database requests via the client program or any of the supported APIs. Cego SQL is very close to SQL language standard as specified with SQL-92. This includes the query commands for inserting, selecting, updating and deleting tuples. The following chapter describes all provided SQL language features of the Cego database system. Each query type is introduced by a syntax description followed by an illustrating sample query.
For a better understanding of the samples, it is recommended to invoke the cgclt client program, connect to a running cego database system and execute the given code.
For a detailed description of the console client program, please refer to the section cgclt.
More advanced users can use one of the provided JDBC , DBD , C or C++ API.
5.1 Fundamentals
Before discussing any SQL statement, some prerequisites are explained.
5.1.1 Datatypes
Cego provides serveral datatypes which can be used as column type for any tables or views but also as in/out parameters for stored procedures.
| Datatype | Meaning |
|---|---|
| int | Integer type |
| long | Long type ( 64 bit ) |
| string(<dim>) | Variable string type of max len <dim> |
| datetime | Date and time values |
| bool | Boolean type |
| bigint(<dim>) | Arbitrary integer type of max len <dim> |
| float | machine dependent floating point type |
| double | machine dependent double point type |
| decimal(<precision>) | decimal value with defined precision |
| decimal(<maxlen>,<precision>) | decimal value with given maximum length and precision |
| smallint | small integer value ( 16 bit ) |
| tinyint | tiny integer value ( 8 bit ) |
| blob | binary large objects |
| clob | character large objects |
5.1.2 Language Tokens
Each programming language consists of a number of tokens as the smallest units of the language. To give a full understanding of Cego SQL, we will first describe the available tokens now. These tokens are used later on for the description of the several query commands.
| Token | Meaning | Regular Expression |
|---|---|---|
| <Id> | Any identifier used for tables, attributes, procedures and so on | [ a-zA-Z ] *[ a-zA-Z0-9_ ] |
| <QualifiedId> | Any identifier used for tables, attributes, procedures and so on | [ a-zA-Z ] *[ a-zA-Z0-9_ ] ( @ | . ) [ a-zA-Z ] *[ a-zA-Z0-9_ ] |
| <VarRef> | Reference to a procedure variable | : [ a-zA-Z ] *[ a-zA-Z0-9_ ] |
| <IntVal> | Basic integer value | ( 0|[1-9]*[0-9]) |
| <StrVal> | Basic string value | ' ... ' |
| <FloatVal> | Floating point value | ( 0|[1-9]*[0-9])'.'*[0-9] |
| <BoolVal> | Boolean value | ( true|false) |
| <Comparison> | Value comparison tokens | ( =|<|>|<=|>=|!=) |
5.1.3 Base Productions
Based on the described token set, in the following are defined some productions which are used in the later defined syntax description tables.
| Symbol | Production |
|---|---|
| <ObjSpec> | <Id> | <QualifiedId> |
| <DataType> | int | long | string '(' <IntVal> ')' | bigint '(' <IntVal> ')' | decimal '(' <IntVal> ')' | decimal '(' <IntVal> ',' <IntVal> ')' | datetime | bool | float | double | smallint | tinyint | blob | clob |
| <Expr> | <Expr> ( + | - | | ) <Term> | <Term> |
| <Term> | <Term> ( * | / ) <Factor> | <Factor> |
| <Factor> | :<Id> | <Constant> | fetch <Id> into ( :<Id> , :<Id> ... ) | <Attribute> | <Function> | ( <Condition> ) | ( <SelectStmt> ) |
| <Constant> |
<StrVal> | <IntVal> | (long) <IntVal> | (bigint) <IntVal> | (smallint) <IntVal> | (tinyint) <IntVal> | <FloatVal> | (double)<FloatVal> | (decimal)<FloatVal> | <BoolVal> |
The detailed syntax of the <SelectStmt> production is described below
5.2 Creating a table
Table objects ( and all other database objects ) are created using the create command. Following the standard SQL, a schema description of the table is given to the create statement
| <CreateStatement> | := | create table <ObjSpec> '(' <Schema> ')' ; |
| <Schema> | := | <Schema> ',' <AttrSpec> |
| <Schema> | := | <AttrSpec> |
| <AttrSpec> | := | [ primary ] <id> <DataType> [ <DefaultOption>] [ <NullOption> ] |
| <DefaultOption> | := | default <Constant> |
| <NullOption> | := | null | not null |
The schema definition specifies the type and name of the table columns. If the keyword primary is added, a primary index for the corresponding column set is created during data table creation.
Please note : primary key columns must be specified as not null
To illustrate the creation of a table, we will create a first table called mytab. The table schema consists of two attribute called a and b of type int and type string. Column a is used as primary key, so it is specified as not null. For the string type, we give a maximum size of 30 bytes.
CGCLT > create table mytab as ( primary a int not null, b string(30) ); Table mytab created ok ( 0.002 s ) |
After creation the table can be described using the desc command.
CGCLT > desc table mytab; +-----------+-----------+-----------+-----------+ | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | | ATTR | TYPE | DEFAULT | NULLABLE | +-----------+-----------+-----------+-----------+ | a | INT | null | no | | b | STRING | null | yes | +-----------+-----------+-----------+-----------+ ok ( 0.002 s ) |
Note, that if not specified, all attribute values are nullable at default. If not null is required, this must be specified
at creation time using the option not null
for the corresponding attribute.
Default values are used for table insert operations to set unspecified columns to appropriate values.
The default extension is used for this purpose.
CGCLT > create table mytab2 as ( primary a int not null, b string(30) default 'Peter'); Table mytab2 created ok ( 0.002 s ) |
Now the table looks like
CGCLT > desc table mytab; +-----------+-----------+-----------+-----------+ | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | | ATTR | TYPE | DEFAULT | NULLABLE | +-----------+-----------+-----------+-----------+ | a | INT | null | no | | b | STRING | Peter | yes | +-----------+-----------+-----------+-----------+ ok ( 0.002 s ) |
5.3 Inserting into a table
If a table object has been created succesfully, it can be filled with data. This can be done using the insert command
| <InsertStatement> | := | insert into <ObjSpec> [ <InsertArgSpec> ] <InsertValueSpec> ; |
| <InsertArgSpec> | := | '(' <InsertArgList> ')' |
| <InsertArgList> | := | <InsertArgList> ',' <Id> |
| <InsertArgList> | := | <Id> |
| <InsertValueSpec> | := | ' values (' <InsertValueList> ')' |
| <InsertValueSpec> | := | <SelectStmt> |
| <InsertValueList> | := | <InsertValueList> ',' <Expr> |
| <InsertValueList> | := | <Expr> |
We will insert a first tuple in our previous created table mytab. Since we have defined two attributes called a and b, we will specify two column values for the insert command in the full qualified manner.
CGCLT > insert into mytab ( a, b ) values ( 42, 'Hello world'); 1 tuples inserted ok ( 0.002 s ) |
Any expression values are also allowed for the insert argument value list. This might be look like the following
CGCLT > insert into mytab ( a, b ) values ( 3*3, 'Hello ' | 'world'); 1 tuples inserted ok ( 0.002 s ) |
The following select query shows the resulting tuple values
CGCLT > select * from mytab; +-----------+-------------------------------+ | mytab_1 | mytab_1 | | a | b | +-----------+-------------------------------+ | 9 | hello world | +-----------+-------------------------------+ ok ( 0.002 s ) |
5.4 Attribute value handling
Cego provides several attribute datatypes to store any user data. In the following, all provided datatypes are described in more detail.
5.4.1 Integer and long values
For numerical values in a range from -2^31 to 2^31, machine dependent integer values can be used in tables as type int. Depending on the machine architecture long values represent 32 or 64bit values in a range of -2^63 to 2^63. To create a table with any int or long values, you just specify the row type as int or long
CGCLT > create table mytab( a int, b long ); Table mytab created ok ( 0.001 s ) |
Integer and long values are inserted as numerical values. You may specify this as
CGCLT > insert into mytab values ( 1, 2 ); 1 tuples inserted ok ( 0.001 s ) |
Please note that numerical values are parsed as integer values and casted internally as needed to long values. To specify long values explicit you have to use the cast operator
CGCLT > insert into mytab values ( 1, (long)234567826353934096 ); 1 tuples inserted ok ( 0.001 s ) |
5.4.2 String values
For string values of any length the string is used.
CGCLT > create table mytab( a string(10), b string(40) ); Table mytab created ok ( 0.001 s ) |
String values are inserted as quated values. You may specify this as
CGCLT > insert into mytab values ( 'hello', 'world' ); 1 tuples inserted ok ( 0.001 s ) |
5.4.3 Boolean values
Boolean columns are defined using the bool datatype
CGCLT > create table mytab( a bool ); Table mytab created ok ( 0.001 s ) |
Boolean values normally inserted as with true or false values. You may specify this as
CGCLT > insert into mytab values ( true ); 1 tuples inserted ok ( 0.001 s ) CGCLT > insert into mytab values ( false ); 1 tuples inserted ok ( 0.001 s ) |
Boolean values also can be given as string or numerical values. In this case, strings of value 'Y' or 'yes' are casted to a true value. Numerical values greater than zero also casted to a true value. All other values are casted to false
CGCLT > insert into mytab values ( 'Y' ); 1 tuples inserted ok ( 0.001 s ) CGCLT > insert into mytab values ( 'yes' ); 1 tuples inserted ok ( 0.001 s ) CGCLT > insert into mytab values ( 1 ); 1 tuples inserted ok ( 0.001 s ) |
5.4.4 Datetime values
In the Cego database system, one data type for any data, time and datetime values can be used. In fact, cego stores the value for any data or time entry in a system time struct value ( time_t ) and provides some powerful conversion functions for scanning and retrieving input and output. To create a table with a datatime value, you just specify the row type as datetime
CGCLT > create table mytab( a datetime ); Table mytab created ok ( 0.001 s ) |
Now, any date and time values can be inserted using the scandate scanning function. This function expects two arguments. First, a format string is given according to the standard unix strftime format specification ( see the strftime man page for a detailed information about format string tokens ). As second, the date value is expected, which must fit the specified format.
CGCLT > insert into mytab values ( scandate('%d.%m.%Y %H:%M:%S %Z', '01.02.2007 2:23:00 CET'));
1 tuples inserted
ok ( 0.001 s )
|
A more comfortable way to insert datetime values are via string casts.
ws > insert into t1 values ( '14.07.2016 12:00:00'); 1 tuples inserted ok ( 0.000 s ) |
The supported datetime formats of the input string value can be customized in the database xml file. Please check section Date format handling for further details, how to customize datetime formats.
5.4.5 Arbitrary integer values
The bigint column type provides arbitray integer handling, which can be used for large integer number. With the type specification, you have to give the dimension for the maximum numbers to store. Please choose this value large enough, so you won't run out of value range.
CGCLT > create table mytab ( a bigint(20) ); Table mytab created ok ( 0.001 s ) |
To avoid confusion with the native integer value, a type casting is expected for any data insert queries.
CGCLT > insert into mytab values ( 2345324533212 ); Mismatched datatype |
Values can be retrieved in a normal way with any select statement.
CGCLT > select * from mytab; +---------------------+ | mytab_1 | | a | +---------------------+ | 2345324533212 | +---------------------+ ok ( 0.002 s ) |
5.4.6 Float values
To store any king of floating values into the Cego database, the datatype float could be used. The float type corresponds to the native float type of the operating system ( 4 byte ).
CGCLT > create table mytab ( a float ); Table mytab created ok ( 0.001 s ) |
Floating type values require a floating point representation of the form <number>.<number>.
CGCLT > create table mytab( a float ); Table mytab created ok ( 0.002 s ) CGCLT > insert into mytab values ( 24.956); 1 tuples inserted ok ( 0.002 s ) CGCLT > select * from mytab; +-----------------------------------------+ | mytab_1 | | a | +-----------------------------------------+ | 24.955999 | +-----------------------------------------+ ok ( 0.003 s ) |
5.4.7 Double values
For a larger precision, the double datatype can be used. double represents the operating system double datatype.
CGCLT > create table mytab ( a double ); Table mytab created ok ( 0.001 s ) |
Double type values require a floating point representation of the form (double)<number>.<number>. Please note, that double types have to be casted to double to avoid confusion with float values.
CGCLT > create table mytab( a double ); Table mytab created ok ( 0.002 s ) CGCLT > insert into mytab values ( (double)24.956); 1 tuples inserted ok ( 0.002 s ) CGCLT > select * from mytab; +----------------------------------------------+ | mytab_1 | | a | +----------------------------------------------+ | 24.956000 | +----------------------------------------------+ ok ( 0.003 s ) |
5.4.8 Decimal values
The Cego decimal datatype stores arbitrary decimal values ( precision is the given parameter ) to the database.
CGCLT > create table mytab( a decimal(2) ); Table mytab created ok ( 0.002 s ) CGCLT > insert into mytab values ( (decimal)1.23); 1 tuples inserted ok ( 0.002 s ) CGCLT > select * from mytab; +-------------------------------+ | mytab_1 | | a | +-------------------------------+ | 1.23 | +-------------------------------+ ok ( 0.003 s ) |
The maximum length of the decimal value can be specified with a second parameter.
CGCLT > create table mytab( a decimal(10,2) ); Table mytab created ok ( 0.020 s ) CGCLT > desc table mytab; +-----------+-----------+-----------+-----------+-----------+-----------+ | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | | ATTR | TYPE | LENGTH | DIM | DEFAULT | NULLABLE | +-----------+-----------+-----------+-----------+-----------+-----------+ | a | decimal | 10 | 2 | null | yes | +-----------+-----------+-----------+-----------+-----------+-----------+ 1 tuples ok ( 0.033 s ) CGCLT > insert into mytab values ( (decimal)24.95); 1 tuples inserted ok ( 0.019 s ) CGCLT > insert into mytab values ( 26.35); 1 tuples inserted ok ( 0.018 s ) lit > select * from mytab; +-----------+ | mytab | | a | +-----------+ | 24.95 | | 26.35 | +-----------+ 2 tuples ok ( 0.053 s ) CGCLT > insert into mytab values ( 26.35876); 1 tuples inserted ok ( 0.019 s ) CGCLT > select * from mytab; +-----------+ | mytab | | a | +-----------+ | 24.95 | | 26.35 | | 26.35 | +-----------+ 3 tuples ok ( 0.028 s ) |
Casts from other datatypes to decimal are done implicitly. Also the required precision is corrected as seen in the samples above.
5.4.9 Small integer values
Smallint columns contain values for small integer values ( 2 byte ).
CGCLT > create table mytab( a smallint ); Table mytab created ok ( 0.002 s ) CGCLT > insert into mytab values ( (smallint)15 ); 1 tuples inserted ok ( 0.002 s ) CGCLT > select * from mytab; +---------+ | mytab_1 | | a | +---------+ | 15 | +---------+ ok ( 0.003 s ) |
5.4.10 Tiny integer values
Tinyint columns contain values for very small integer values ( 1 byte ).
CGCLT > create table mytab( a tinyint ); Table mytab created ok ( 0.003 s ) CGCLT > desc table mytab; +----------------------------------------+ | ObjectName : mytab | | ObjectType : table | +-------------+---------------+----------+ | Attribute | Type | Nullable | +-------------+---------------+----------+ | a | tinyint | y | +-------------+---------------+----------+ ok ( 0.002 s ) CGCLT > insert into mytab values ( (tinyint)5); 1 tuples inserted ok ( 0.002 s ) CGCLT > select * from mytab; +---------+ | mytab_1 | | a | +---------+ | 5 | +---------+ ok ( 0.003 s ) |
5.4.11 Lob values
Normally the size of a table value is restricted to the page size of the database. Lobs are stored in one or more dedicated data pages and in this sense, any kind of binary or character information can be stored. The stored data can just be accessed by using several provided lob functions, which is shown in the following samples.
CGCLT > create table mytab( a clob ); Table mytab created ok ( 0.003 s ) CGCLT > desc table mytab; +----------------------------------------------------+ | ObjectName : mytab | | ObjectType : table | +-------------+---------------+-----------+----------+ | Attribute | Type | Default | Nullable | +-------------+---------------+-----------+----------+ | a | clob | null | y | +-------------+---------------+-----------+----------+ ok ( 0.001 s ) |
For any insert or update operation, clob values can be used in the same manner as string values. The database system takes care of an internal conversion.
CGCLT > insert into mytab values ( 'hello world' ); 1 tuples inserted ok ( 0.003 s ) CGCLT > select * from mytab; +---------+ | mytab_1 | | a | +---------+ | [32] | +---------+ ok ( 0.003 s ) |
To access the clob values, the internal clob function clob2str can be used. This function retrieves the stored clob value and converts it to a string. This clobsize function returns the byte length of the clob as a long value. For performance reasons, the database handles references to clob values in a way, that the same clob value can be referenced by several clob entries ( e.g. copied via an insert by select ). To indicate the number of references for a clob, the clobref function can be used.
CGCLT > select clob2str(a) from mytab; +-------------------+ | FUNC | | clob2str(mytab.a) | +-------------------+ | hello world | +-------------------+ 1 tuples ok ( 0.003 s ) CGCLT > select clobsize(a) from mytab; +---------------------+ | FUNC | | clobsize(mytab.a) | +---------------------+ | 12 | +---------------------+ 1 tuples ok ( 0.000 s ) CGCLT > select clobref(a) from mytab; +---------------------+ | FUNC | | clobref(mytab.a) | +---------------------+ | 1 | +---------------------+ 1 tuples ok ( 0.000 s ) |
Blob values are handled in a similar way, but the values can not be accessed directly via the cgclt program. For this, one of the provided C/C++/JDBC API should be used.
CGCLT > create table mytab( a blob ); Table mytab created ok ( 0.003 s ) CGCLT > desc table mytab; +----------------------------------------------------+ | ObjectName : mytab | | ObjectType : table | +-------------+---------------+-----------+----------+ | Attribute | Type | Default | Nullable | +-------------+---------------+-----------+----------+ | a | blob | null | y | +-------------+---------------+-----------+----------+ ok ( 0.001 s ) |
Please note : You should not do any kind of blob reference operations manually
5.4.12 Insert by select
A convenient way to load existing table data into another table is using the insert-by-select statement. The result set of the corresponding select statement is stored into the table specified with the insert statement.
CGCLT > insert into mytargettab ( a, b ) select a, b from mysourcetab; 1 tuples inserted ok ( 0.002 s ) |
Please note, that the table schema of the target table must match with the selection list given to the select statement or at least a datatype cast from source attribute type to the target attribute type must be possible.
5.4.13 Bulk insert
To improve performance, one insert statement can contain a bunch of tuples, which are then all added to the corresponding table.
CGCLT > insert into t1 values ( 1, 'alpha'), (2, 'beta'), (3, 'gamma'); 3 tuples inserted ok ( 0.000 s ) |
This way might be useful in case of large table loads, where the table import could be splitted in bulk insert statements of an appropriate size.
5.5 Selecting from a table
To retrieve data from one or more tables, the SQL select statement is used. Cego SQL supports select queries in a common way as specified with the following grammar definition.
| <SelectStatement> | := | select <Selection> from <TableSource> [ <WhereClause> ] [ <GroupClause> ] [ <OrderingClause> ] [ <RowLimitOpt> ] [ <UnionAllOptOpt> ]; |
| <Selection> | := | ( [ distinct ] <SelectionList> | * ) |
| <SelectionList> | := | <SelectItem> , <SelectItem>, ... |
| <SelectItem> | := | <Expr> [ as <Alias> ] |
| <SelectItem> | := | <Aggregation> |
| <Aggregation> | := | ( count(*) | (count|sum|avg|min|max) (<Expr>) ) |
| <TableSource> | := | where <Condition> ) |
| <TableSource> | := | <TableList> |
| <TableSource> | := | <JoinSpecList> |
| <JoinSpecList> | := | <JoinSpecList JoinSpec> |
| <JoinSpecList> | := | <Table> <JoinSpec> |
| <JoinSpec> | := | <InnerJoin> <Table> on <QueryCondition> |
| <JoinSpec> | := | left outer join <Table> on <QueryCondition> |
| <JoinSpec> | := | right outer join <Table> on <QueryCondition> |
| <InnerJoin> | := | ( inner join | join ) |
| <TableList> | := | <Table> , <TableList> |
| <TableList> | := | <Table> |
| <Table> | := | <ObjSpec> |
| <Table> | := | <ObjSpec> <Id> |
| <WhereClause> | := | where <Condition> ) |
| <Condition> | := | ( <Condition> ( and | or ) <Predicate> | <Predicate> ) |
| <Predicate> | := | ( exists|not exists) ( <SelectStatement> ) |
| <Predicate> | := | <Expr> ( in|not in) ( <SelectStatement> ) |
| <Predicate> | := | <Expr> ( in|not in) ( <ExprList> ) |
| <ExprList> | := | <Expr>, <ExprList> |
| <ExprList> | := | <Expr> |
| <Predicate> | := | <Expr> <Comparison> ( <SelectStatement> ) |
| <Predicate> | := | <Expr> <Comparison> <Expr> |
| <Predicate> | := | <Expr> between <Expr> and <Expr> |
| <Predicate> | := | <Expr> ( like | not like | nclike | not nclike ) <StrVal> |
| <Predicate> | := | <Expr> |
| <GroupClause> | := | group by <GroupList> <HavingClause> |
| <GroupList> | := | <GroupList> , <Attribute> |
| <GroupList> | := | <Attribute> |
| <OrderingClause> | := | order by <OrderingList> |
| <OrderingList> | := | <OrderingList> , <Expr> <OrderingOpt> |
| <OrderingList> | := | <Expr> <OrderingOpt> |
| <OrderingOpt> | := | [ (asc|desc) ] |
| <HavingClause> | := | having <Expr> <Comparison> <Expr> |
| <RowLimitOpt> | := | rowlimit <IntVal> |
| <UnionAllOpt> | := | [ union all <SelectStatement> ] |
| <Attribute> | := | ( <Id> | <Id> . <Id> ) |
| <Constant> | := | ( [ (bigint) ] <IntVal> | <StrVal> | [ (decimal) ]<FloatVal> | <BoolVal> | null | sysdate ) |
In the following, some sample select statements are given. We use our previously created table mytab for this.
It is out of the scope of this user guide, to give a full SQL language description. Just the basics
and Cego specific features are discussed here.
The star selection selects all attributes of the corresponding table. Without any where condition, all tuples of the table
are selected.
CGCLT > select * from mytab; +-----------+-------------------------------+ | | | | a | b | +-----------+-------------------------------+ | 33 | xxx | | 44 | foo | | 66 | hello world | +-----------+-------------------------------+ ok ( 0.014 s ) |
To be more specific, we might select the column a from mytab and list the tuple, where the value of a is 44.
CGCLT > select a from mytab where a = 44; +-----------+ | | | a | +-----------+ | 44 | +-----------+ ok ( 0.002 s ) |
Please note: If using attribute conditions in the where clause, it might be useful to create an appropriate index for the corresponding attribute.
How to create and use table indexes are discussed later on in the section Using Indexes
To create in index object on attribute afor the table above, just execute the query create index i1 on mytab(a);
5.5.1 Selection
In the selection part of a query, the output colums are specified, which should retrieved and calculated. In this sense, the selection is a list of function calls, expressions, terms, factors or just simple attributes. Following the syntax definition listed above, expressions can be combined and nested as needed.
CGCLT > select a, b, c, (a+b+c)/3 from t2; +-----------+-----------+-----------+---------------+ | | | | | | a | b | c | ((a+(b+c))/3) | +-----------+-----------+-----------+---------------+ | 1 | 2 | 3 | 2 | | 5 | 5 | 5 | 5 | +-----------+-----------+-----------+---------------+ ok ( 0.015 s ) |
For string attributes the concatenation operator |
is also allowed to concatenate the corresponding attribute values.
CGCLT > select a, b, a | ' ' | b from t3; +----------------+----------------+----------------+ | | | | | a | b | a|' '|b | +----------------+----------------+----------------+ | hello | world | hello world | +----------------+----------------+----------------+ ok ( 1.808 s ) |
If unique, attributes can be specified without table identifier. Otherwise, the name or alias of the table must be given.
CGCLT > select ta.a, tb.a from t2 ta, t2 tb; +-----------+-----------+ | | | | a | a | +-----------+-----------+ | 1 | 1 | | 1 | 5 | | 5 | 1 | | 5 | 5 | +-----------+-----------+ ok ( 0.010 s ) |
In the sample above, the alias names ta and tb are used to identify the attribute a for the selfjoined table t2 clearly.
5.5.2 Alias
In the previous query, the attribute a is indicated two times, one for table ta and one for table tb. In some cases, it is useful to distinguish attributes or rename the resulting columns for any other reasons. For this, an aliasing of the column names is needed.
CGCLT > select ta.a as A1, tb.a as A2 from t2 ta, t2 tb; +-----------+-----------+ | | | | A1 | A2 | +-----------+-----------+ | 1 | 1 | | 1 | 5 | | 5 | 1 | | 5 | 5 | +-----------+-----------+ ok ( 0.010 s ) |
5.5.3 Joins
Any data table can be correlated with any other data table ( or itself ) using table joins. In fact, table joins are the cartesian product
of the two or more tables. Normally, the database user is just interested in a those result tuples of the join, which meet an appropirate join condition.
For this, attribute conditions for the tables are added in the where clause.
In the following, we will look at some samples for simple join constructions.
Assume the following two table are created
CGCLT > select * from t1; +-----------+-------------------------------+ | | | | a | b | +-----------+-------------------------------+ | 14 | hello | | 15 | ciao | | 22 | goodbye | +-----------+-------------------------------+ ok ( 0.003 s ) CGCLT > select * from t2; +-----------+-------------------------------+ | | | | a | b | +-----------+-------------------------------+ | 22 | guy | | 23 | you | | 14 | world | +-----------+-------------------------------+ ok ( 0.002 s ) |
Now we want to join t1 with t2 by using attribute a for the join condition.
CGCLT > select * from t1 ta, t2 tb where ta.a = tb.a; +-----------+-------------------------------+-----------+-------------------------------+ | | | | | | a | b | a | b | +-----------+-------------------------------+-----------+-------------------------------+ | 14 | hello | 14 | world | | 22 | goodbye | 22 | guy | +-----------+-------------------------------+-----------+-------------------------------+ ok ( 0.009 s ) |
To be more restrictive, furthermore we can filter out just those lines where a has a value of 14.
CGCLT > select * from t1 ta, t2 tb where ta.a = tb.a and ta.a = 14; +-----------+-------------------------------+-----------+-------------------------------+ | | | | | | a | b | a | b | +-----------+-------------------------------+-----------+-------------------------------+ | 14 | hello | 14 | world | +-----------+-------------------------------+-----------+-------------------------------+ ok ( 0.013 s ) |
5.5.4 Conditions
As seen in the previous section, conditions can be used to reduce the tuple result set to the required values.
In general a condition consists of a set of predicates combined with logical and/or operators.
A predicate can be a comparison with a constant value or with another attribute value, as also seen in the samples above.
Furthermore predicates can contain null values or like comparisons shown in the following sample
CGCLT > select * from otab1 where a like 'l%'; +-------------------------------+-----------+ | otab1_1 | otab1_1 | | a | b | +-------------------------------+-----------+ | lida | 4 | | lida | 6 | | lemke | 12 | | lemke | 22 | | lemke | 8 | +-------------------------------+-----------+ ok ( 0.005 s ) |
All tuples are listed where the value of attribute a starts with the letter l
.
5.5.5 Distinct
To distinct operator is used to just select distinct result tuples. The distinction relates to all referenced attributes which occur in the selection part of the quers. For plain queries this is obvious. Consider the content of the following table
CGCLT > select a, b from t1; +-----------+-----------+ | t1 | t1 | | a | b | +-----------+-----------+ | 1 | alpha | | 2 | beta | | 2 | beta | | 3 | beta | +-----------+-----------+ 4 tuples ok ( 0.005 s ) |
If the distinct operator is added, this results in the following
CGCLT > select distinct a, b from t1; +-----------+-----------+ | t1 | t1 | | a | b | +-----------+-----------+ | 1 | alpha | | 2 | beta | | 3 | beta | +-----------+-----------+ 3 tuples ok ( 0.000 s ) |
For aggregation queries, also all distinct tuples are treated
CGCLT > select distinct count(a) from t1; +-----------------------+ | AGGR | | distinct count(t1.a) | +-----------------------+ | 3 | +-----------------------+ 1 tuples ok ( 0.000 s ) CGCLT > select distinct count(b) from t1; +-----------------------+ | AGGR | | distinct count(t1.b) | +-----------------------+ | 2 | +-----------------------+ 1 tuples ok ( 0.000 s ) |
Please note, that for distinct aggreation, dedicated queries must be used for each aggreation attribute. The following query can lead to an undesirable result, since the distinction of all references attributes is treated.
CGCLT > select distinct count(a), count(b) from t1; +-----------------------+-----------------------+ | AGGR | AGGR | | distinct count(t1.a) | distinct count(t1.b) | +-----------------------+-----------------------+ | 3 | 3 | +-----------------------+-----------------------+ 1 tuples ok ( 0.000 s ) |
Since for grouping queries, all result tuples are distinct because of the grouping attributes, the distinct option has no effect
CGCLT > select distinct a, count(*) from t1 group by a; +-----------+--------------------+ | t1 | AGGR | | a | distinct count(*) | +-----------+--------------------+ | 1 | 1 | | 2 | 2 | | 3 | 1 | +-----------+--------------------+ 3 tuples ok ( 0.003 s ) |
5.5.6 Ordering
If a ordered listing of the result tuples is required, a ordering condition can be given with the select statement.
CGCLT > select * from t1 order by a; +-----------+-------------------------------+ | t1_1 | t1_1 | | a | b | +-----------+-------------------------------+ | 12 | erwin | | 13 | ida | | 14 | udo | | 30 | aze | | 30 | aaa | | 30 | anton | +-----------+-------------------------------+ ok ( 0.007 s ) |
If more ordering attributes are given, ordering is evaluated for all attribute values
CGCLT > select * from t1 order by a, b; +-----------+-------------------------------+ | t1_1 | t1_1 | | a | b | +-----------+-------------------------------+ | 12 | erwin | | 13 | ida | | 14 | udo | | 30 | aaa | | 30 | anton | | 30 | aze | +-----------+-------------------------------+ ok ( 0.007 s ) |
5.5.7 Grouping
The grouping clause enables the user to aggregate tuple values grouped by the given grouping attribute. Any kind of aggregation is allowed for grouping.
CGCLT > select a, count(*) from t1 group by a order by a; +-----------+-----------+ | t1_1 | | | a | COUNT(*) | +-----------+-----------+ | 12 | 1 | | 13 | 1 | | 14 | 1 | | 30 | 3 | +-----------+-----------+ ok ( 0.008 s ) |
5.5.8 Having
In addition with the grouping clause, a having condition can be used for further filtering.
CGCLT > select a, count(*) from t1 group by a order by a having count(*) = 1; +-----------+-----------+ | t1_1 | | | a | COUNT(*) | +-----------+-----------+ | 12 | 1 | | 13 | 1 | | 14 | 1 | +-----------+-----------+ ok ( 0.008 s ) |
5.5.9 Nested query
Subselects may be useful for some special query purpuses. In general, it is recommended to use table joins
instead of nested queries for performance reasons.
Select those suppliers, which deliver no material
CGCLT > select sname from supplier sup where snr not in ( select mat.snr from material mat); |
Select those suppliers, which can deliver all ordered material
CGCLT > select sname from supplier sup where not exists ( select * from orders ord where not exists ( select * from material mat where mat.snr = sup.snr and mat.mname = ord.mname )); |
Subselects can also be used in the selection of a query. The following sample lists all material and the corresponding supplier using a nested select in the selection part.
CGCLT > select mname, ( select sname from supplier sup where sup.snr = mat.snr ) from material mat; |
5.5.10 Inner Join
As a more modern form of a table join, an inner join statement, can be used to create the cartesian product of two tables. The condition of the join is specified in the on clause as shown below.
CGCLT > select * from t1 inner join t2 on t1.a = t2.a; |
The tuple result is the same as using a traditional where condition t1.a = t2.a.
5.5.11 Outer Join
Outer joins are used to select all tuples of one of the joined tables, no matter if the join condition matches or not. The non matching columns of joined table are filled with null values. Either left outer or right outer joins may be specified, depending on what table should be selected completely. Both join methods are described in more detail in the following.
5.5.11.1 Left outer join
In case of a left outer join, all row values of the left table object are expanded. If the condition does not fit any row of the right table object, null values are indicated.
CGCLT > select * from t1 left outer join t2 on t1.a = t2.c; +-----------+-------------------------------+-----------+-------------------------------+ | t1_1 | t1_1 | t2_2 | t2_2 | | a | b | c | d | +-----------+-------------------------------+-----------+-------------------------------+ | 1 | xxx | 1 | xxx | | 4 | yyy | null | null | +-----------+-------------------------------+-----------+-------------------------------+ ok ( 0.008 s ) |
5.5.11.2 Right outer join
In case of a right outer join, all row values of the right table object are expanded. If the condition does not fit any row of the left table object, null values are indicated.
CGCLT > select * from t1 tx right outer join t2 ty on tx.a = ty.c; +-----------+-------------------------------+-----------+-------------------------------+ | tx | tx | ty | ty | | a | b | c | d | +-----------+-------------------------------+-----------+-------------------------------+ | 1 | xxx | 1 | xxx | | null | null | 2 | vvv | | null | null | 3 | zzz | +-----------+-------------------------------+-----------+-------------------------------+ ok ( 0.008 s ) |
5.5.12 Union all
To concatenate the rows of two or more select statements, a union all clause can be used. As a prerequisite, the resulting output schema of all select statements must be compatible. This might be achieved by natural or by appropriate type casts and aliases.
First, we give a sample of compatible schemas
CGCLT > desc table t1; +-----------+-----------+-----------+-----------+-----------+-----------+ | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | | ATTR | TYPE | LENGTH | DIM | DEFAULT | NULLABLE | +-----------+-----------+-----------+-----------+-----------+-----------+ | a | int | 4 | 0 | null | yes | | b | string | 10 | 0 | null | yes | +-----------+-----------+-----------+-----------+-----------+-----------+ 2 tuples ok ( 0.000 s ) CGCLT > desc table t2; +-----------+-----------+-----------+-----------+-----------+-----------+ | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | | ATTR | TYPE | LENGTH | DIM | DEFAULT | NULLABLE | +-----------+-----------+-----------+-----------+-----------+-----------+ | c | int | 4 | 0 | null | yes | | d | string | 30 | 0 | null | yes | +-----------+-----------+-----------+-----------+-----------+-----------+ 2 tuples ok ( 0.000 s ) CGCLT > select a, b from t1; +-----------+-----------+ | t1 | t1 | | a | b | +-----------+-----------+ | 1 | alpha | | 2 | beta | | 1 | alpha | | 2 | beta | | 3 | gamma | +-----------+-----------+ 5 tuples ok ( 0.000 s ) CGCLT > select a, b from t2; +-----------+-------------------------------+ | t2 | t2 | | a | b | +-----------+-------------------------------+ | 42 | xxx | | 43 | yyy | | 44 | zzz | +-----------+-------------------------------+ 3 tuples ok ( 0.000 s ) CGCLT > select a, b from t1 union all select a, b from t2; +-----------+-----------+ | t1 | t1 | | a | b | +-----------+-----------+ | 1 | alpha | | 2 | beta | | 1 | alpha | | 2 | beta | | 3 | gamma | | 42 | xxx | | 43 | yyy | | 44 | zzz | +-----------+-----------+ 8 tuples ok ( 0.000 s ) |
If the schemas do not match, casts and aliases are required
CGCLT > desc table t3; +-----------+-----------+-----------+-----------+-----------+-----------+ | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | | ATTR | TYPE | LENGTH | DIM | DEFAULT | NULLABLE | +-----------+-----------+-----------+-----------+-----------+-----------+ | x | string | 10 | 0 | null | yes | | y | string | 20 | 0 | null | yes | +-----------+-----------+-----------+-----------+-----------+-----------+ 2 tuples ok ( 0.000 s ) litdev > select a, b from t1 union all select str2int(x) as a, y as b from t3; +-----------+-----------+ | t1 | t1 | | a | b | +-----------+-----------+ | 1 | alpha | | 2 | beta | | 1 | alpha | | 2 | beta | | 3 | gamma | | 1 | XXX | | 2 | FFF | | 3 | UUU | +-----------+-----------+ 8 tuples ok ( 0.000 s ) |
5.5.13 Numeric functions
There are several numeric functions available in cego
| Function | Description |
|---|---|
| round(<expr1>[,<expr2>]) | Rounding the expression in the first argument to the precision in the second argument. The precision is zero, if the second argument is missing |
| mod(<expr1>, <expr2>) | The function returns on a integer based arithmetic the remainder of expr1 divided by expr2 |
| div(<expr1>, <expr2>) | The function returns on a integer based arithemtic the division of expr1 and expr2 |
| ldiv(<expr1>, <expr2>) | The function returns on a long based arithmetic the division of expr1 and expr2 |
| lmod(<expr1>, <expr2>) | The function returns on a long based arithmetic the remainder of expr1 divided expr2 |
| power(<expr1>, <expr2>) | The function returns expr1 raised to the expr2 power based on integer values |
| bitand(<expr1>,<expr2>) | Bitwise and operation on integer values |
| bitor(<expr1>,<expr2>) | Bitwise or operation on integer values |
| bitxor(<expr1>,<expr2>) | Bitwise xor operation on integer values |
| randint(<expr>) | Generates a randon integer value between 0 and the maxium value given with the expression ( integer value expected ) |
| int2asc(<expr>) | Converts the integer value to its corresponding ascii character ( integer between 0 and 127 expected ) |
5.5.14 String functions
For string manipulation, cego provides a number of functions with can be used for any statement.
Each of the function described in the following expects one or more expression arguments, which can be
any valid expression as already seen.
As a function return value either a result string or an integer value is returned to the caller.
| Function | Description |
|---|---|
| trim(<expr1>,<expr2>) | Removes any leading and trailing characters specified in expr2 from the given expression expr1 and returns the resulting string |
| ltrim(<expr1>,<expr2>) | Removes any leading characters specified in expr2 from the given expression expr1 and returns the resulting string |
| rtrim(<expr1>,<expr2>) | Removes any trailing characters specified in expr2 from the given expression expr1 and returns the resulting string |
| lower(<expr>) | Converts the given expression to lower case characters |
| upper(<expr>) | Converts the given expression to upper case characters |
| left(<expr1>,<expr2>) | Returns expr2 characters from the left end of the string evaluated with expr1. Please note that expr2 is expected to be an integer value |
| right (<expr1>,<expr2>) | Returns expr2 characters from the right end of the string evaluated with expr1. Please note that expr2 is expected to be an integer value |
| substr(<expr1>,<expr2>) | Returns the substring of string expr1 at position expr2 to the end |
| substr(<expr1>,<expr2>,<expr3>) | Returns the substring of string expr1 at position expr2and length expr3 |
| getpos(<expr1>,<expr2>) | Returns the position of substring expr2 in given expression expr1 |
| getpos(<expr1>,<expr2>,<expr3>) | Returns the position of substring expr2 in given expression expr1 starting search at position given with expr3 |
| getpos(<expr1>,<expr2>,<expr3>,<expr4>) | Returns the position of expr4 occurence of substring expr2 in given expression expr1 starting search at position given with expr3 |
| length(<expr>) | Returns the length of expr |
| replace(<expr1>,<expr2>,<expr3>) | For the given expression expr1 replace the substring given with expr1 substring expr2 with substring expr3 and returns the resulting string |
| repmatch(<searchpattern1>,<replacepattern>,<source3>,<nummatch3> ) | For the given seachpattern and replacepattern the source is mapped to the corresponding target and the result is returned by the function. The optional reference parameter nummatch returns the number of matches. For a detailed desription of the regmatch function, see the cooresponding section |
| str2int(<expr>) | Converts the given expression to an integer value |
| str2long(<expr>) | Converts the given expression to a long value |
| randstr(<expr>) | Generates a random string of length given with the expression value ( integer value expected ) |
| asc2int(<expr>) | Converts the character in the given expression to the corresponding ascii integer value ( string with len 1 expected ) |
We give a sample for the function substr
CGCLT > create table mytab( a string(30) ); Table mytab created ok ( 0.003 s ) CGCLT > insert into mytab values ( 'This is a string'); 1 tuples inserted ok ( 0.002 s ) CGCLT > select substr(a,6,2) from mytab; +-----------------------+ | | | substr(mytab_1.a,6,2) | +-----------------------+ | is | +-----------------------+ ok ( 0.006 s ) |
5.5.14.1 Regmatch function
If a more sophisticated pattern replacement is needed, the regmatch function can be used.
Based on POSIX regular expression syntax, a search pattern can be defined and given as a first argument to the function.
As a second argument, a replace pattern is expected. The matched subexpression of the searchpattern ( enclosed with "(" )
can be referenced with $1 ... $9.
The third argument is the source string, which should be mapped.
As a result, the mapped string is returned by the function.
cgclt > select regmatch('([a-zA-Z]*)[.]([a-zA-Z]*)', '$2 $1', 'Hello.World');
+-------------------------------------------------------------+
| FUNC |
| regmatch('([a-zA-Z]*)[.]([a-zA-Z]*)','$2 $1','Hello.World') |
+-------------------------------------------------------------+
| World Hello |
+-------------------------------------------------------------+
1 tuples
ok ( 0.001 s )
|
With the optional fourth parameter, a reference variable can be given to return the number of matches.
cgclt > set n =0;
Value assigned
ok ( 0.000 s )
cgclt > select regmatch('([a-zA-Z]*)[.]([a-zA-Z]*)', '$2 $1', 'Hello.World', :n);
+----------------------------------------------------------------+
| FUNC |
| regmatch('([a-zA-Z]*)[.]([a-zA-Z]*)','$2 $1','Hello.World',:n) |
+----------------------------------------------------------------+
| World Hello |
+----------------------------------------------------------------+
1 tuples
ok ( 0.001 s )
cgclt > print :n;
1
ok ( 0.000 s )
|
5.5.15 Date functions
The following date functions are available
| Function | Description |
|---|---|
| newdate(<expr1> , <expr2> ... ) | Converts the given numeric arguments to a datetime value Arguments are year, month, day, hour, minute and second. If any of the parameters are ommittted, the minimum value is set up. Samples : newdate(2017,8) results in 01.08.2017 00:00:00 newdate(2017,8, 12, 10) results in 12.08.2017 10:00:00 |
| date2str(<expr1> , <expr2> ) | Converts the the given datetime value in expr1 to a formatted string. The format is specified with expr2 |
| scandate(<expr1> , <expr2> ) | The scandate function parses the string given with <expr2> and the date format given wit <expr1>. The date format string corresponds to the format tring of the standard strptime c library function |
| date2long(<expr>) | Converts the the given datetime value in the expr argument to a long value. The long value represents the datetime value in seconds since january, 01, 1970 ( Unix time convention ) |
| long2date(<expr>) | Converts the the given long value to a datetime value |
To retrieve a date or time value, the date2str can be used to print the date value in an appropriate way. The date2int and int2date functions can be used to perform any arithmetic date operations.
CGCLT > select date2str(a, '%H:%M') from mytab; +-----------------------------+ | | | date2str(mytab_1.a,'%H:%M') | +-----------------------------+ | 02:23 | +-----------------------------+ ok ( 0.003 s ) |
The format string for the second parameter corresponds to the standard unix date format string as specified with the
strftime library function.
The date2int function provides a conversion of the datetime value to an integer value
CGCLT > select date2int(a) from mytab; +---------------------+ | FUNC | | date2int(mytab_1.a) | +---------------------+ | 1170292980 | +---------------------+ ok ( 0.003 s ) CGCLT > select int2date(date2int(a) + 60 * 60 * 24) from mytab; +----------------------------------------------+ | FUNC | | int2date(date2int(mytab_1.a) + 60 * 60 * 24) | +----------------------------------------------+ | 02.02.2007 02:23:00 | +----------------------------------------------+ ok ( 0.003 s ) |
Datetime functions can be combined with any other functions and can also be used for
evaluation purposes
To select all entries for the year 2010 and beyond, you can use the following query
CGCLT > select a from mytab where str2int(date2str(a, '%Y')) >= 2010; +-------------------------------+ | mytab | | a | +-------------------------------+ | 29.10.2010 12:00:42 | +-------------------------------+ ok ( 0.002 s ) |
5.5.16 Blob functions
The following blob functions are available
| Function | Description |
|---|---|
| blobsize(<expr1> ) | Retrieves the size for the given blob Expression must return a valid blob value |
| blobref(<expr1> ) | Retrieves the number of references for the given blob Expression must return a valid blob value |
5.5.17 clob functions
The following blob functions are available
| Function | Description |
|---|---|
| clobsize(<expr1> ) | Retrieves the size for the given clob Expression must return a valid clob value |
| clobref(<expr1> ) | Retrieves the number of clob references for the given clob Expression must return a valid clob value |
| clob2str(<expr1> ) | Retrieves the coresponding string value for the given clob Expression must return a valid clob value |
5.5.18 Arithmetic functions
Actually, there are no arithmetic functions implemented.
| Function | Description |
|---|---|
| N/A (<N/A> ) | N/A |
5.5.19 Case when clause
The case-when-clause is used in a selection query to implement a mapping from a condition to any expression values. The clause is used in a similar way as known from common programming languages. to distinguish several cases, the when condition may appear several times.
CGCLT > select case when a = 1 then 'alpha' when a = 2 then 'beta' else 'gamma' end from t1; +---------------------+ | CASE CONDITION | | case when ... | +---------------------+ | alpha | | alpha | | beta | | beta | | gamma | +---------------------+ ok ( 0.003 s ) |
5.5.20 Execution plan
For query performance analysis, it may be useful to see what strategy the database uses to retrieve the selected tuples.
An execution plan of each select statement can be retrieved without executing the given query.
Before the select statement, just put the keyword plan and cego will inform you about the join strategy.
You will get information about what way cego will use to scan through the table ( full table scan or index based )
and the order, the tables are read.
In the first sample, we print the execution plan of a simple select statement for table mytab.
Since no condition is specified and all tuples of the table should be retrieved, cego decides to use
a full table scan in the target table.
CGCLT > plan select * from mytab; Execution Plan : +------------------------------------------------------------------------------+ | PLAN | | DESCRIPTION | +------------------------------------------------------------------------------+ | Execution plan | | --------------- | | Joining mytab(mytab_1) with full table scan | +------------------------------------------------------------------------------+ ok ( 0.001 s ) |
As second, the query is performed on table t1 with an available index on attribute a. For this query, select will use this index to retrieve all tuples, matching the index condition.
CGCLT > plan select * from t1 where a = 42; +------------------------------------------------------------------------------+ | PLAN | | DESCRIPTION | +------------------------------------------------------------------------------+ | Execution plan | | --------------- | | Joining t1(t1_1) with full index trace on t1.a = 42 | +------------------------------------------------------------------------------+ ok ( 0.002 s ) |
Also queries including views and sub query are analyzed in detail. The following sample illustrates the execution plan for a more complex query
CGCLT > plan select a from t1, v1 where t1.a = t1.a and v1.b not in ( select b from t3 where a = 47 and exists ( select b from t3 ) ) and exists ( select a from t1 ); +------------------------------------------------------------------------------+ | PLAN | | DESCRIPTION | +------------------------------------------------------------------------------+ | Execution plan | | --------------- | | Joining table t1 (t1) with full table scan with no condition | | Joining view v1 (v1) | | Execution plan for v1 | | ---------------------- | | Joining table t1 (t1) with full table scan using condition t1.b = 'XX' | | Execution plan for subquery | | ---------------------------- | | Joining table t3 (t3) with full table scan using condition t3.a = 47 | | Execution plan for subquery | | ---------------------------- | | Joining table t3 (t3) with full table scan with no condition | | Execution plan for subquery | | ---------------------------- | | Joining table t1 (t1) with full table scan with no condition | +------------------------------------------------------------------------------+ ok ( 0.001 s ) |
5.5.21 System tables
System tables contain information about tableset objects. A system table cannot be modified but information about the tableset objects can be retrieved. System table are identified by the $ prefix. Here is an example
CGCLT > select * from $table; +---------------------+ | $table_1 | | NAME | +---------------------+ | tab1 | | tab2 | | tab3 | +---------------------+ ok ( 0.002 s ) |
The available system objects can be retrieved with the list command
CGCLT > list sysobj; +---------------------------------------------------+ | SysObj | | Name | +---------------------------------------------------+ | table | | procedure | | view | | index | | btree | | key | | bustat | +---------------------------------------------------+ 7 tuples ok ( 0.073 s ) |
5.6 Updating a table
To change the values of some tuples, the update statement is used. The changing columns have to be specified with the new values and the changing rows have to qualified by the where clause.
| <UpdateStatement> | := | update <ObjSpec> [ <Alias> ] set <UpdateList&t; [ <WhereClause> ] [ <ReturnOpt> ] ; |
| <UpdateList> | := | <UpdateList> , <Assignment> |
| <UpdateList> | := | <Assignment> |
| <Assignment> | := | <Id> = <Expr> |
| <ReturnOpt> | := | return <ReturnVarList> |
| <ReturnVarList> | := | <ReturnVarList> , <ReturnVar> |
| <ReturnVarList> | := | <ReturnVar> |
| <ReturnVar> | := | <VarRef> = <Expr> |
The sample below updates the table mytab in a kind, that all values of column a are set to value 222 and all values of column b are set to value 'foo' where column a matches the value of 33
CGCLT > update mytab set a = 222, b = 'foo' where a = 33; 1 tuples updated ok ( 0.002 s ) |
You also can use select queries in the update assignment with references to the current updated tuple.
CGCLT > select * from t1; +-----------+---------------------+ | t1_1 | t1_1 | | a | b | +-----------+---------------------+ | 1 | alpha | | 2 | beta | | 3 | gamma | +-----------+---------------------+ ok ( 0.002 s ) CGCLT > select * from t2; +-----------+---------------------+ | t2_1 | t2_1 | | a | b | +-----------+---------------------+ | 1 | xxx | | 2 | xxx | | 3 | xxx | +-----------+---------------------+ ok ( 0.002 s ) CGCLT > update t2 set b = ( select b from t1 where a = t2.a ); 3 tuples updated ok ( 0.003 s ) CGCLT > select * from t2; +-----------+---------------------+ | t2_1 | t2_1 | | a | b | +-----------+---------------------+ | 1 | alpha | | 2 | beta | | 3 | gamma | +-----------+---------------------+ ok ( 0.002 s ) |
With the return option, updated values from the corresponding table may be returned to the calling session. The return option can be used for updating multiple rows, where just the last row result would be stored to the given procedure variables. By using return on first just the first matching tuple is updated and the result is returned. If no tuple was found, the result tuple just contains null values. The values are stored in the given variables as shown in the following
CGCLT > select * from t1; +-----------+---------------------+ | t1 | t1 | | a | b | +-----------+---------------------+ | 1 | Alpha | | 2 | Beta | | 3 | Gamma | | 4 | Gamma | | 5 | Gamma | +-----------+---------------------+ 5 tuples ok ( 0.000 s ) CGCLT > set a=0; Value assigned ok ( 0.000 s ) CGCLT > update t1 set a = a + 1 where b = 'Gamma' return on first :a = a; 1 tuples updated ok ( 0.000 s ) CGCLT > print :a; 4 ok ( 0.000 s ) CGCLT > select * from t1; +-----------+---------------------+ | t1 | t1 | | a | b | +-----------+---------------------+ | 1 | Alpha | | 2 | Beta | | 4 | Gamma | | 5 | Gamma | | 4 | Gamma | +-----------+---------------------+ 5 tuples ok ( 0.000 s ) CGCLT > CGCLT > update t1 set a = a + 1 where b = 'Gamma' return :a = a; 3 tuples updated ok ( 0.000 s ) CGCLT > print :a; 5 ok ( 0.000 s ) CGCLT > select * from t1; +-----------+---------------------+ | t1 | t1 | | a | b | +-----------+---------------------+ | 1 | Alpha | | 2 | Beta | | 5 | Gamma | | 6 | Gamma | | 5 | Gamma | +-----------+---------------------+ 5 tuples ok ( 0.000 s ) |
Return on updates might be useful if the updated value should be retrieved in one transaction. For example, this could be used for individual counters or update state tables.
5.7 Deleting from a table
To delete tuples, which have been inserted into a table, you have to use the delete statement as seen below
| <DeleteStatement> | := | delete from <ObjSpec> [ <Alias> ] [ <WhereClause> ] ; |
The defintion of the where clause is quite the same as seen for the select statement. If no where clause is given, all tuples of the table are deleted.
CGCLT > delete from mytab where a = 44; 1 tuples deleted ok ( 0.045 s ) |
5.8 Truncating a table
If the content of a table table is not needed anymore, it can be deleted in a fast way using the truncate statement.
CGCLT > truncate table mytab; Table mytab truncated ok ( 0.001 s ) |
5.9 Dropping a table
If a table is not needed anymore, it can be removed with the drop statement. If the table is dropped, all corresponding index and key entries are also dropped by the drop statement.
CGCLT > drop table mytab; Table mytab dropped ok ( 0.001 s ) |
To avoid an error if the corresponding table does not exists anymore, for the drop operation an if-exists option can be added.
CGCLT > drop if exists table mytab_not_exist; Table does not exist ok ( 0.001 s ) |
5.10 Altering a table
Sometimes, it is required to change the structure of a datatable. Any table columns or table contraints should be added or removed. For this, the alter statement can be used.
The following syntax is defined for this
| <AlterStatement> | := | alter table <ObjSpec> <AlterList> ; |
| <AlterList> | := | <AlterOption> , <AlterList> |
| <AlterList> | := | <AlterOption> |
| <AlterOption> | := | drop column <Id> |
| <AlterOption> | := | add column <ColumnDesc> |
| <AlterOption> | := | modify column <ColumnDesc> |
| <AlterOption> | := | rename column <Id> to <Id> |
| <RenameStatement> | := | rename <ObjType> <ObjSpec> to <Id> ; |
| <ObjType> | := | table | index | btree | key | procedure | view | check |
The following sample illustrates the altering of a table
CGCLT > create table mytab( a string(30) ); Table mytab created ok ( 0.003 s ) CGCLT > insert into mytab values ( 'This is a string'); 1 tuples inserted ok ( 0.002 s ) CGCLT > alter table mytab add column b int; Table altered ok ( 0.002 s ) CGCLT > select * from mytab; +-------------------------------+-----------+ | mytab_1 | mytab_1 | | a | b | +-------------------------------+-----------+ | This is a string | null | +-------------------------------+-----------+ ok ( 0.004 s ) |
Please note, that you can just add nullable columns, since all existing row values for the new added column are set to null.
Table columns are dropped using the drop clause for the alter statement.
CGCLT > alter table mytab drop column b; Table altered ok ( 0.001 s ) CGCLT > select * from mytab; +-------------------------------+ | mytab_1 | | a | +-------------------------------+ | This is a string | +-------------------------------+ ok ( 0.003 s ) |
Object renaming can be done using the rename query command.
CGCLT > rename table mytab to mytab2; Object renamed ok ( 0.002 s ) |
5.11 Using indexes
For constraint and performance reasons, index tables are important data objects within a relational database. Originally, index have been implemented based on AVL binary tree, which still can be used, but are not recommended. Since version 2.16 and up, btree+ index objects are supported which are recommended for any index objects. Both types of index objects can be used in the same manner. It is recommended to use btree index objets, since the creation time and space consumption is much less than for AVL index objects.
Index objects are created using the following statements
| <CreateIndexStatement> | := | create primary ( avltree | index| btree ) on <Id> ( <AttrList> ); |
| <CreateIndexStatement> | := | create [ unique ] ( avltree | index| btree ) <Id> on <Id> ( <AttrList> ); |
This results in three types of Cego index objects
- Primary index
- Unique index
- Ordinary index
Primary index objects are used for primary key implementation in a way, that the index is unique and the attribute values must be not null. Primary indexes can either be created within data table creation using the primary key clause, or explicit using the primary key word. Just one primary key is allowed per table. To use foreign keys, a primary key defintion must exist for the corresponding table. Unique and ordinary indexes are used for further table indexing. Multiple definitions can be used, depending on the data model requirements
CGCLT > create table mytab2 ( a int not null, b string(30) ); Table mytab2 created ok ( 0.002 s ) CGCLT > create primary index on mytab2 ( a ); Primary index created ok ( 0.001 s ) CGCLT > create btree b1 on mytab2 ( b ); BTree b1 created ok ( 0.001 s ) |
5.11.1 Index check
The AVL algorithm used for Cego index tables requires tree balancing information for each node entry. The verify the consisteny of a created index, a check can be performed on a created index. If the index check was successful, the height of the index tree is printed.
CGCLT > create avltree a1 on t1(a); Index a1 created ok ( 0.003 s ) CGCLT > check avltree a1; Index ok ( Height = 12 ) ok ( 0.001 s ) |
Please note: Any check routine for btree objects is actually not available
5.12 Using foreign keys
In databases, referential constraints ( also called foreign keys ) are used to ensure consistency of the user data in terms of referential integrity. In this sense, a foreign key column of a data tables refers to any primary key ( either of the same or a different data table ). This avoids a row insertion for those rows, where a reference key does not exist but also row deletion, if this would lead to a constraint violation.
| <AlterForeignKeyStatement> | := | alter table <Id> add foreign key <Id> ( <AttrList> ) references <Id> ( <AttrList> ); |
| <AttrList> | := | <Id> , <Id> , ... |
In the following, we give an example, how to create a foreign key object for a previous created table mytab.
CGCLT > create table mytab2 ( primary x int not null, a int ); Table mytab2 created ok ( 0.002 s ) CGCLT > alter table mytab2 add foreign key myfkey ( a ) references mytab ( a ); Foreign key myfkey created ok ( 0.001 s ) |
5.13 Using check constraints
Check constraints are useful, if you would like to restrict table data to a valid subset instead of all possible values of the corresponding datatype. A check constraint is added to a table and is defined as a condition, which contains any predicates with attributes of the table.
| <AlterCheckConstraintStatement> | := | alter table <Id> add check <Id> on <Condition>; |
CGCLT > create table mytab2 ( primary a int not null, b int ); Table mytab2 created ok ( 0.002 s ) CGCLT > alter table mytab2 add check chk1 on a < 1000; Check chk1 created ok ( 0.001 s ) CGCLT > insert into mytab2 values ( 1000, 10); Error : Check constraint chk1 violated Query failed ok ( 0.001 s ) CGCLT > insert into mytab2 values ( 100, 10); 1 tuples inserted ok ( 0.001 s ) |
Please note, that actually sub selects are not supported in check constraint conditions.
5.14 Using table aliases
To refer to table data using an alternate tablename and alternate attribute names, table alias could be used. Other than view objects, which can be accesed read only, table alias objects can be accessed read / write. A table objects can be created with the following statement.
| <CreateAliasStatement> | := | create alias <Id> on <Id> ( <AliasList> ); |
| <AliasList> | := | <Alias> , <AliasList> |
| <AliasList> | := | <Alias> |
| <Alias> | := | <Id> as <Id> |
CGCLT > create alias myalias on t1 ( a as ax, b as bx ); Alias myalias created ok ( 0.002 s ) |
5.15 Views
Any ( complicated ) select queries, which should be used in a more convenient form can be encapsulated into view statements. A view statement contains the defined select statement as defined with the create view statement. If the view is accessed, the evaluation of the select statement is done and the tuple result is returned as same as calling the native select statement. The view then can be used as a normal table object inside other select statements.
| <CreateViewStatement> | := | create view <Id> as <SelectStatement> ; |
To demonstrate the usage of views, two native tables are created and a view is created based on these two tables.
CGCLT > create table tab1 ( primary a int, b string(30)); Table tab1 created ok ( 0.003 s ) CGCLT > create table tab2 ( primary a int, b int, c string(30)); Table tab2 created ok ( 0.003 s ) CGCLT > create view v1 as select t1.a , t1.b , t2.c from tab1 t1, tab2 t2 where t1.a = t2.a; View v1 created ok ( 0.002 s ) |
The view now can be used as a normal table object.
CGCLT > select count(*) from v1; ok ( 0.002 s ) |
Views can be removed using the drop operation.
CGCLT > drop if exists view v1; ok ( 0.002 s ) |
In combination with the if-exists option, the drop operation will not fail in case that the view does not exist anymore.
5.16 Procedures
Stored procedures enable the database programmer to encapsulate database specific application code directly into the database.
With the cego database system, stored procedures are provided in the same way as for several other database systems.
A procedure has to be created inside a SQL batch script, embedding the create statement with the delimiter sign @.
Stored procedures must have a unique name and a number of input and output parameters.
Optionally, a procedure return value can be specified to turn the procedure into a function.
Within the procedure, several database queries may occur but also control blocks for loops and conditions.
From cego version 2.51 and up, query conditions and procedure conditions have been merged, which result in an extended syntax for stored procedures. For definition of the Condition grammar production, please check section for a description of the condition clause.
| <ProcCreateStatement> | := | create procedure <Id> ( <ParameterList> ) [ <ReturnOption> ] begin <ProcStmtBlock> end ; |
| <ParameterList> | := | <Parameter> , <Parameter> ... |
| <ReturnOpt> | := | <Id> return <Datatype> |
| <Parameter> | := | <Id> ( in | out ) <Datatype> |
| <ProcStmtBlock> | := | <ProcStatementList> <ProcExceptionList> |
| <ProcStatementList> | := | <ProcStatementList> ; <ProcStatement> |
| <ProcStatementList> | := | <ProcStatement> ; |
| <ProcStatement> | := | var <Id> <DataType> |
| <ProcStatement> | := | cursor <Id> as <SelectStatement> |
| <ProcStatement> | := | close <Id> |
| <ProcStatement> | := | <Id> = <Expr> |
| <ProcStatement> | := | <Expr> |
| <ProcStatement> | := | throw <Expr> |
| <ProcStatement> | := | if <Condition> then <ProcStmtBlock> *[ elsif <Condition> then <ProcStmtBlock> ] [ else <ProcStmtBlock> ] end |
| <ProcStatement> | := | while <Condition> begin <ProcStmtBlock> end |
| <ProcStatement> | := | <InsertStatement> |
| <ProcStatement> | := | <UpdateStatement> |
| <ProcStatement> | := | <DeleteStatement> |
| <ProcStatement> | := | start transaction |
| <ProcStatement> | := | commit |
| <ProcStatement> | := | rollback |
| <ProcStatement> | := | lock table <Id> |
| <ProcStatement> | := | unlock table <Id> |
| <ProcStatement> | := | return <Expr> ; |
| <ProcStatement> | := | return ; |
| <ProcExceptionList> | := | <ProcExceptionList> <ProcExceptionStmt> |
| <ProcExceptionStmt> | := | exception when <ProcExceptionType> then <ProcStatementList> |
| <ProcExceptionType> | := | core_op | other | any |
If a single SQL statement does not provide enough power, a stored
procedure might be useful. In general, stored procedures are used to
encapsulate application specific SQL code inside the database. This
can be useful for performance reasons, but also for code maintenance.
To illustrate the usage of stored procedures in Cego, the following small sample is given.
5.16.1 Procedure sample 1 - Simple table copy
drop table srctab;
drop table desttab;
drop procedure copytab;
create table srctab ( primary a int, b string(30));
create table desttab ( primary a int, b string(30));
insert into srctab values ( 1, 'fred');
insert into srctab values ( 2, 'mark');
insert into srctab values ( 3, 'berta');
insert into srctab values ( 4, 'john');
insert into srctab values ( 5, 'anna');
@
create procedure copytab ( copyCond in int ) return int
begin
var copyCount int;
:copyCount = 0;
var ca int;
var cb string(30);
cursor copyCursor as select a, b from srctab where a = :copyCond;
while fetch copyCursor into ( :ca, :cb ) = true
begin
insert into desttab values ( :ca, :cb );
:copyCount = :copyCount + 1 ;
end;
return :copyCount;
end;
@
set a = 3;
set r = 0;
:r = call copytab(:a);
print 'Number of rows copied : ' | :r;
|
A procedure called copytab is created which copies the table srctab to the table desttab. To demonstrate the usage of procedure input parameters, a copy condition is given which must match the selected tuple from srctab. If finished successful, the procedure returns the number of copied rows with the procedure return value.
To execute the procedure, both tables must be available. So at the beginning of the sample, the tableset is cleaned up and both tables are created. Please note, that we have to create an index on attribute a in srctab to satisfy the where condition in the select statement.
Some tuples are inserted in srctab as the demo data.
Next, the procedure is created. Since the procedure contains semicolon signs for statement separation, but the procedure creation statement should be given to the parser as a single statement, we need to encapsulate the create statement into the special characters @
.
The procedure is created with on input parameter called copyCond of type integer. The procedure returns a value of type int.
Inside the create statement, the procedure variable copyCount is declared using the var keyword and it is initialized to zero. Two other variables called ca and cb are declared, to store the fetched data from the select statement. Then a cursor is declared with the conditioned select statement on table srctab.
A while loop is used to trace through the srctab table. The fetch predicate is used as the loop invariant. If no more data can be fetched, a value of false is returned and the loop is terminated.
The while loop block consits of two statement. An insert statement, to store the fetched values into desttab and a variable assignment to increase the copy counter. After the loop has been finished, the variable copy counter is returned to the caller.
Now the procedure can be called. In an Cego SQL interpreter, variables can also be used outside of procedures. We set up two variables named a and r to be used as the input value and to store the return value of the procedure.
At last, the procedure is called and the return value is printed out
To test the given sample, put the code into a file called procsample.sql. Assuming the Cego database backend is running on localhost port 2200 and tableset TS1 is started, you can invoke the Cego client program with the following command
$ cgclt --server=localhost --port=2200 --user=lemke/lemke --batchfile=procsample.sql |
5.16.2 Procedure sample 2 - Insert with id counter
create table orders (primary onr int not null, mname string(30), orderdate datetime);
create table ids ( primary id string(30) not null, idval int);
insert into ids values ('ONR', 10000);
@
create procedure nextId ( id in string(30) ) return int
begin
var actId int;
var res bool;
cursor actIdCur as select idval from ids where id = :id;
:actId = 0;
if fetch actIdCur into ( :actId ) = true
then
close actIdCur;
:actId = :actId + 1;
update ids set idval = :actId where id = :id;
end;
return :actId;
end;
@
@
create procedure new_order (mname in string(30) ) return int
begin
var onr int;
:onr = nextId('ONR');
insert into orders values ( :onr, :mname, sysdate );
return :onr;
end;
@
:onr = call new_order('spoon');
:onr = call new_order('screw');
:onr = call new_order('hammer');
select * from orders;
|
A smarter form of the nextId procedure can be implemented using the update return clause. The return clause enables the caller to store any updated values of the corresponding statement into procedure variables.
@ create procedure nextId ( id in string(30) ) return int begin var nextVal int; update ids set idval = idval + 1 where id = :id return :nextVal = idval; return :nextVal; end; @ |
5.16.3 Procedure sample 3 - Exception Handling
A cego procedure allows you to catch several exceptions, which can occur during query execution. The exception part is added at the end of a procedure block and is introduced with exception when followed by the exception which should be catched. The following exception can be catched
| Exception | Meaning |
|---|---|
| core_op | Error which occured during execution of a statment |
| other | User thrown exceptions |
| any | Any exception is catched |
More information about the exception is stored in the special procedure block variable excep_info of type string. The value of excep_info can be assigned to a return or output parameter of the calling procedure.
@
create procedure myexcep ( resultinfo out string(30) ) return int
begin
var c int;
-- table does not exist, exception core_op is thrown
insert into XXX values ( 1000, 'xxx' );
:c = ( select count(*) from t1 );
if :c > 3
then
throw 'Too many inserts';
end;
:resultinfo = 'OK';
return 0;
exception when core_op
then
-- exception for invalid objects is catched here
:resultinfo = :excep_info;
return 1;
exception when other
then
-- exception is catched, exception information is assigned from special var excep_info to return parameter
:resultinfo = :excep_info;
return 2;
end;
@
set x = 'XXX';
:r = call myexcep(:x);
print :r;
print :x;
drop procedure myexcep;
|
If a procedure is not used anymore, it can be dropped.
CGCLT > drop procedure nextId; Procedure dropped ok ( 0.001 s ) |
Procedures can also be dropped in combination with the if-exists option
CGCLT > drop if exists procedure nextId_notexist; Procedure does not exist ok ( 0.001 s ) |
5.17 Trigger
Database triggers are used to perform further database operations before or after any insert, update or delete operation. If triggers are not used carefully, this might result in complex and difficult to maintain database configurations. From my perspective, triggers should mostly be used, if the corresponding database application can not handle the required operations or if it is not possible to encapsulate the operation with the trigger into a dedicated stored procedure.
| <CreateTriggerStatement> | := | create trigger <Id> ( before | after ) <TriggerConditionList> on begin <ProcStmtBlock> end |
| <TriggerConditionList> | := | <TriggerConditionList> or <TriggerCondition> |
| <TriggerConditionList> | := | <TriggerCondition> |
| <TriggerCondition> | := | ( insert | update | delete ) |
Here comes a sample for a trigger configuration
drop if exists table t1; create table t1 ( a int, b string(30)); drop if exists table t2; create table t2 ( c int, d string(30)); drop if exists table t3; create table t3 ( m string(50)); @ create trigger tg1 before insert on t1 begin -- while t1 in increasing, t2 is decreasing delete from t2 where c = a; end; @ @ create trigger tg2 before update on t1 begin -- store update protocol in t3 var s string(30); :s = 'T1 updated at ' | sysdate | ' to ' | b; insert into t3 values ( :s ); end; @ list trigger; show trigger tg1; show trigger tg2; insert into t2 values ( 1, 'XXX'); insert into t2 values ( 2, 'XXX'); insert into t2 values ( 3, 'XXX'); insert into t2 values ( 4, 'XXX'); insert into t1 values ( 1, 'HUGO'); select * from t2; insert into t1 values ( 2, 'HUGO'); select * from t2; insert into t1 values ( 3, 'HUGO'); select * from t2; select * from t3; update t1 set b = 'Bert' where a = 1; update t1 set b = 'Gabi'; update t1 set b = 'Werner'; select * from t3; |
If a trigger is not used anymore, it can be dropped. Like all other database objects, this can also be done in a defensive way using the if-exists clause
CGCLT > drop if exists trigger tg1; Trigger tg1 dropped ok ( 0.001 s ) |
5.18 Counter
Counter objects provide a convenient way to manage unique id values. All counters are of type long, but are casted to the appropriate datatype ( int, smallint, tinyint ). A counter object is created and used inside a tableset as described in the following.
5.18.1 Adding a counter
Before using a counter, one has to be added to a tableset. A counter is added with the following command
CGCLT > create counter mycounter; Counter added ok ( 0.001 s ) |
5.18.2 Listing counters
Counters can be listed with the following command
CGCLT > list counter; +-------------------------------+-------------------------------+ | Counter | Counter | | Name | Value | +-------------------------------+-------------------------------+ | hurz | 0 | | iwan | 7 | | mycounter | 0 | +-------------------------------+-------------------------------+ ok ( 0.002 s ) |
5.18.3 Using a counter
To access counters, the internal function nextcount should be used. Each method call increases the corresponding counter.
CGCLT > insert into t1 values ( nextcount(mycounter) ); 1 tuples inserted ok ( 0.001 s ) |
5.18.4 Setting a counter
A counter value can be set to a specific value
CGCLT > create counter c1; Counter created ok ( 0.000 s ) CGCLT > set counter c1 to 30; Counter c1 set ok ( 0.000 s ) CGCLT > list counter; +-------------------------------+-------------------------------+ | Counter | Counter | | Name | Value | +-------------------------------+-------------------------------+ | c1 | 30 | +-------------------------------+-------------------------------+ ok ( 0.002 s ) CGCLT > create table t1 ( a int ); Table t1 created ok ( 0.001 s ) CGCLT > insert into t1 values ( 1220); 1 tuples inserted ok ( 0.001 s ) CGCLT > set counter c1 to ( select a from t1 ); Counter c1 set ok ( 0.001 s ) CGCLT > list counter; +-------------------------------+-------------------------------+ | Counter | Counter | | Name | Value | +-------------------------------+-------------------------------+ | c1 | 1220 | +-------------------------------+-------------------------------+ ok ( 0.002 s ) CGCLT > set counter c1 to ( select count(*) from t1 ); Counter c1 set ok ( 0.001 s ) CGCLT > list counter; +-------------------------------+-------------------------------+ | Counter | Counter | | Name | Value | +-------------------------------+-------------------------------+ | c1 | 1 | +-------------------------------+-------------------------------+ ok ( 0.002 s ) |
5.18.5 Geting the current value of a counter
To retrieve the value of a specific counters, the internal function getcount can be used.
CGCLT > select getcount(mycounter) ); +---------------------+ | FUNC | | getcount(mycounter) | +---------------------+ | 1 | +---------------------+ 1 tuples ok ( 0.033 s ) |
5.18.6 Dropping a counter
If a counter is not used anymore, it can be dropped.
CGCLT > drop counter mycounter; Counter dropped ok ( 0.001 s ) |
For a more defensive kind, you can also use the if exists clause.
CGCLT > drop if exists counter mycounter; Counter dropped ok ( 0.001 s ) |
Please note, that counter values are not recovered after a system crash. They should be adjusted using a tableset init file, which can be defined and is executed after tableset startup
5.19 Tableset information commands
Beside the native SQL query commands, other commands are available for database and tableset information retrievel.
5.19.1 uptime
The uptime command indicates the overall uptime of the bufferpool. In fact, this is also the uptime of the database.
CGCLT > uptime; +---------------------------------------------------+ | BUFFERPOOL | | UPTIME | +---------------------------------------------------+ | 3 days, 12:37:54 | +---------------------------------------------------+ 1 tuples ok ( 0.081 s ) |
5.19.2 show
With the show command, information about several kind of the selected tableset database objects can be retrieved.
To get an overview about the current status of the bufferpool, you can use the show pool command. Status information about all pages of the bufferpool is printed out.
CGCLT > show pool; +---------------------+---------------------+ | POOLINFO | POOLINFO | | PARAMETER | VALUE | +---------------------+---------------------+ | Page Size | 16384 | | Total Pages | 12000 | | Used Pages | 4287 | | Free Pages | 7713 | | Dirty Pages | 5 | | Fixed Pages | 0 | | Persistent Pages | 59 | | No Sync Pages | 0 | | Spread Rate | 1.115 | | ------------------- | ------------------- | | Stat Start | 10.11.2018 11:05:56 | | Hit Rate | 95.08% | | Cur Fix Count | 91394 | | Max Fix Count | 100000 | | Avg Fix Try | 5 | | Disk Reads | 4499 | | Disk Writes | 32 | | Read Delay | 0.040 msec | | Write Delay | 5.584 msec | | ------------------- | ------------------- | | Pool Uptime | 1d 3:36:13 | +---------------------+---------------------+ 21 tuples ok ( 0.125 s ) |
Please note, that the output of show pool is not tableset dependent.
To get usage information about the allocated datafiles, you can use the show systemspace command
CGCLT > show systemspace; +-----------+-----------+-----------+ | | | | | SPACE | NUMPAGES | USEDPAGES | +-----------+-----------+-----------+ | SYSTEM | 200 | 2 | | TEMP | 200 | 1 | | DATAFILE | 5000 | 5000 | | DATAFILE | 5000 | 602 | | DATAFILE | 5000 | 0 | | DATAFILE | 5000 | 0 | | DATAFILE | 5000 | 0 | | DATAFILE | 5000 | 0 | | DATAFILE | 5000 | 0 | | DATAFILE | 5000 | 0 | | DATAFILE | 5000 | 0 | | DATAFILE | 5000 | 0 | +-----------+-----------+-----------+ ok ( 0.017 s ) |
The show command can also be used to list procedure or view defintions as stored in the database.
CGCLT > show procedure copytab; +-------------------------------------------------------------+ | PROCTEXT | | copytab | +-------------------------------------------------------------+ | procedure copytab(copycond in int) return int | | begin | | var copycount int; | | var ca int; | | var cb string(30); | | :copycount = 0; | | cursor copycursor as | | select a, | | b | | from srctab@TS1 srctab_1 | | where a = :copycond; | | while fetch copycursor into (:ca, :cb) = true | | begin | | insert into desttab values (:ca, :cb); | | :copycount = :copycount - 1; | | end; | | return :copycount; | | end; | +-------------------------------------------------------------+ ok ( 0.001 s ) |
CGCLT > show view v1; +-------------------------------------------------------------+ | VIEWTEXT | | v1 | +-------------------------------------------------------------+ | view v1 as | | select * | | from t1@TS1 t1_1; | +-------------------------------------------------------------+ ok ( 0.001 s ) |
5.19.3 list
An overview about several database objects can be retrieved with the list <object type> command. <objecttype> is one of the following values
- tableset
- table
- index
- btree
- view
- procedure
- key
- counter
- sysobj
- tmpobj
- check
For example, all user tables in the selected tableset are listed with the following command
CGCLT > list table; +-------------------------------+ | | | TABLENAME | +-------------------------------+ | t1 | | mytab | +-------------------------------+ ok ( 0.005 s ) |
5.19.4 tableinfo
To get a list of all releated objects for a table, you can retrieve information using the tableinfo command. The command lists all related indexes, foreign keys and checks for the corresponding table.
CGCLT > tableinfo t1; +-------------------------------+----------------+ | TABLEINFO | TABLEINFO | | NAME | TYPE | +-------------------------------+----------------+ | t1 | table | | b1 | btree | +-------------------------------+----------------+ ok ( 0.000 s ) |
5.19.5 tablesize
To get more detailed info about a single table object, you can retrieve information using the tablesize command. The command lists all related objects ( indexes and foreign keys ) but also the used tableset space in pages. For btree object, the relevance is indicated which is the number of distinct entries. ( The join optimizer takes the btree object with the strongest relevance )
CGCLT > tablesize t1; +-------------------------------+----------------+----------------+----------------+ | TABLEINFO | TABLEINFO | TABLEINFO | TABLEINFO | | NAME | TYPE | PAGES | RELEVANCE | +-------------------------------+----------------+----------------+----------------+ | t1 | table | 1 | 0 | | b1 | btree | 1 | 2 | +-------------------------------+----------------+----------------+----------------+ ok ( 0.000 s ) |
5.19.6 tupleinfo
To inspect the tuple status for a single table, the tupleinfo command might be useful. The number of overall rows but also transaction based committed, deleted, inserted and obsolete rows are indicated.
CGCLT > tupleinfo t1; +----------------+----------------+----------------+----------------+----------------+ | TUPLEINFO | TUPLEINFO | TUPLEINFO | TUPLEINFO | TUPLEINFO | | ROWS | COMMITTED | DELETED | INSERTED | OBSOLETE | +----------------+----------------+----------------+----------------+----------------+ | 2534 | 0 | 0 | 0 | 0 | +----------------+----------------+----------------+----------------+----------------+ 1 tuples ok ( 0.000 s ) |
The following tuple states may occur
- COMMITTED - Tuple is already commited by an ongoing transaction
- DELETED - Tuple is marked to be deleted
- INSERTED - Tuple is marked as new
- OBSOLETE - A tuple which has been inserted and then deleted inside the same transaction
5.19.7 desc
Table column information for table objects can be retrieved with the desc statement. The column name, it's datatype and the corresponding nullable flag is printed.
CGCLT > desc table mytab; +-----------+-----------+-----------+-----------+-----------+ | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | | ATTR | TYPE | LENGTH | DEFAULT | NULLABLE | +-----------+-----------+-----------+-----------+-----------+ | a | INT | 4 | null | yes | | b | STRING | 30 | null | yes | +-----------+-----------+-----------+-----------+-----------+ ok ( 0.002 s ) |
CGCLT > desc index i1; +-----------+-----------+-----------+-----------+ | TABLEDESC | TABLEDESC | TABLEDESC | TABLEDESC | | ATTR | TYPE | DEFAULT | NULLABLE | +-----------+-----------+-----------+-----------+ | b | STRING | null | yes | +-----------+-----------+-----------+-----------+ ok ( 0.002 s ) |
With the desc command, also procedure and view interfaces can be retrieved.
CGCLT > desc procedure checkinout; +-----------+-----------+-----------+-----------+ | PROCDESC | PROCDESC | PROCDESC | PROCDESC | | ATTR | TYPE | LENGTH | INOUT | +-----------+-----------+-----------+-----------+ | inval | STRING | 30 | in | | inval2 | INT | 4 | in | | outval | STRING | 30 | out | +-----------+-----------+-----------+-----------+ ok ( 0.001 s ) |
CGCLT > desc view matview; +-----------+-----------+-----------+ | VIEWDESC | VIEWDESC | VIEWDESC | | ATTR | TYPE | LENGTH | +-----------+-----------+-----------+ | sname | STRING | 30 | | mname | STRING | 30 | +-----------+-----------+-----------+ ok ( 0.001 s ) |
5.19.8 sync
The sync command enables the database user, to force a checkpoint for the current tableset. In this sense, all dirty pages of the bufferpool are written to the datafiles and a logfile switch is performed.
CGCLT > sync; TableSet TS1 in sync ok ( 0.002 s ) |
Please note : The sync operation is performed in a synchronous way, this means that the prompt just returns, if all data is written completely. For large database configurations, this may take a while.
5.20 Reorganisation
During the lifetime of a database table, size is increased caused by insert update or delete. Especially if append mode is enabled, the table is not searched for free data slots but instead data is appended to the end of the table. This may result in empty data pages which are still allocated to the table. To free these empty pages, a table reorganisation is required
CGCLT > tablesize t1; +-------------------------------+----------------+----------------+ | TABLEINFO | TABLEINFO | TABLEINFO | | NAME | TYPE | PAGES | +-------------------------------+----------------+----------------+ | t1 | table | 24 | +-------------------------------+----------------+----------------+ ok ( 0.002 s ) CGCLT > reorganize table t1; Table t1 reorganized ok ( 0.001 s ) CGCLT > tableinfo t1; +-------------------------------+----------------+----------------+ | TABLEINFO | TABLEINFO | TABLEINFO | | NAME | TYPE | PAGES | +-------------------------------+----------------+----------------+ | t1 | table | 11 | +-------------------------------+----------------+----------------+ ok ( 0.003 s ) |
Please note: Reorganisation on a table just affects the specified object. Reorganisation of index object must be done explicitly.
5.21 Append mode
If any insert or update operations on tables are performed, new tuples are added to a table.
Adding tuples can be done in two ways. If performance is the major issue, tuples
can be appended to a table instead of searching the whole table for an appropriate free data slot.
Especially for very large tables, appending data can increase the insert performance significantly.
With append mode enabled, excessive insert and update operations let the table increase very fast, which requires
a reorganization of the table to free all unused emty pages.
The database user hase to decide depending on the corresponding query or the performance requirements,
if append mode is appropriate or not.
Append mode can be enabled or disabled on the fly with the following queries
To disable append mode
CGCLT > set append off; Append mode disabled; ok ( 0.000 s ) |
And to enable append mode
CGCLT > set append on; Append mode enabled ok ( 0.000 s ) |
Please note: Append mode is set globally for the database session and affects all corresponding data and index tables.
The following sample illustrated the effect of enabling or disabling append mode
create table t1 ( primary a int not null, b string(10));
@
create procedure filltab ( c in int ) return int
begin
var i int;
:i = 0;
while :i < :c
begin
insert into t1 values ( :i, 'AAAAAAA');
:i = :i + 1;
end;
return :i;
end;
@
@
create procedure updtab ( c in int ) return int
begin
var i int;
:i = 0;
while :i < :c
begin
update t1 set b = 'xxxx' where a = :i;
:i = :i + 1;
end;
return :i;
end;
@
|
First, we fill the table with some data and perform some update operations on it
CGCLT > call filltab(10000); Procedure filltab executed ok ( 2.049 s ) CGCLT > call updtab(10000); Procedure updtab executed ok ( 9.799 s ) CGCLT > tableinfo t1; +-------------------------------+----------------+----------------+ | TABLEINFO | TABLEINFO | TABLEINFO | | NAME | TYPE | PAGES | +-------------------------------+----------------+----------------+ | t1 | table | 71 | | t1_pidx | primary index | 93 | +-------------------------------+----------------+----------------+ ok ( 0.002 s ) CGCLT > call updtab(10000); Procedure updtab executed ok ( 9.877 s ) CGCLT > tableinfo t1; +-------------------------------+----------------+----------------+ | TABLEINFO | TABLEINFO | TABLEINFO | | NAME | TYPE | PAGES | +-------------------------------+----------------+----------------+ | t1 | table | 107 | | t1_pidx | primary index | 139 | +-------------------------------+----------------+----------------+ ok ( 0.003 s ) |
Now we disable the append mode and call the update procedure another time
CGCLT > set append off; Append mode disabled ok ( 0.000 s ) CGCLT > call updtab(10000); Procedure updtab executed ok ( 11.086 s ) CGCLT > tableinfo t1; +-------------------------------+----------------+----------------+ | TABLEINFO | TABLEINFO | TABLEINFO | | NAME | TYPE | PAGES | +-------------------------------+----------------+----------------+ | t1 | table | 107 | | t1_pidx | primary index | 139 | +-------------------------------+----------------+----------------+ ok ( 0.003 s ) |
The tableinfo command indicates no more grow of the table since the tuples are inserted in already allocated but unused pages. But update performance has decreased since the search for free slots takes additional time.
5.22 Grace mode
Several database objects can depend on each other. If a tableset is exported using the cgclt dump option, a reload of the exported sql file might result in object creation errors, since the referenced objecs are still not available. To avoid these errors, the grace mode must be enabled. In grace mode, referred objects are not checked for existance and the corresponding database objects could be created. If the referred objects is still not available at runtime, this results in a runtime error.
The tableset grace mode is enabled for the current tableset with the following command
CGCLT > set grace on; Grace mode enabled ok ( 0.000 s ) |
With enabled grace mode, a script like the sample below can be loaded without errors. A database view is created, which refers to a non-existing procedure and a procedure is created, which refers to a non-existing view.
set grace on;
drop if exists table bill;
create table bill ( primary billid int not null, netto decimal(10,2));
insert into bill values ( 1, 12.23);
insert into bill values ( 2, 67.11);
-- we create a view, which uses non existing procedure getVat
drop if exists view plainvat;
create view plainvat as
select getVat() as vat;
-- now we create a procedure, which uses non-existing view vatview
drop if exists procedure getVat;
@
create procedure getVat() return decimal(10,2)
begin
var vat decimal(10,2);
:vat = ( select vat from vatview );
return :vat;
end;
@
-- we provide vatview now
drop if exists view vatview;
create view vatview as
select (decimal)0.19 as vat;
-- no critical dependencies anymore on billview
drop if exists view billview;
create view billview as
select billid as billid,
netto as netto,
getVat() * netto as vat
from bill;
-- verify billview, objects are recompiled
select * from billview;
select * from vatview;
select * from plainvat;
set grace off;
|
5.23 BTree Cache
For very large tables, the creation of btree objects is pretty much time consuming. Since the btree is managed as same as other table objects, the data pages are accesed via the buffer pool. During creation, the btree must be reorganized which results in many bufferpool read and write requests. For small buffer pool configurations, this slows down the performance significantly. Since the creation of a btree is not critical in terms of data consistency, it is useful to use a dedicated memory buffer for this. It has been observed, that for a table of about 100 million tuples, the creation tome was reduced from about 20 hours to 2.5 hours by using the btree cache.
The btree cache is used with the cached option given wit the create btree command. Please note the the btree cache allocates additional memory for the build up procedure.
CGCLT > create btree b1 on t1(a) cached; Btree b1 created ok ( 0.039 s ) |
5.23.1 BTree Cache Performance
To illustrate the performance of the btree cache, the picture below shows the progress of the btree creation time with enabled and disabled btree cache. The system, which was used for this measurement, was a Intel Core i7 CPU, 16 GB Memory and a Fusion Disk Drive ( combined SSD and hard disk drive ) running OSX El Capitan.
It can be seen, that the btree creation time with disabled cache increases with an exponential growth, while the growth is rather linear with enabled cache. For systems with non SSD storage, is has been observed that the curve for disabled btree cache raises much faster. Of course this requires enough heap memory available for the dynamic allocation of the btree.
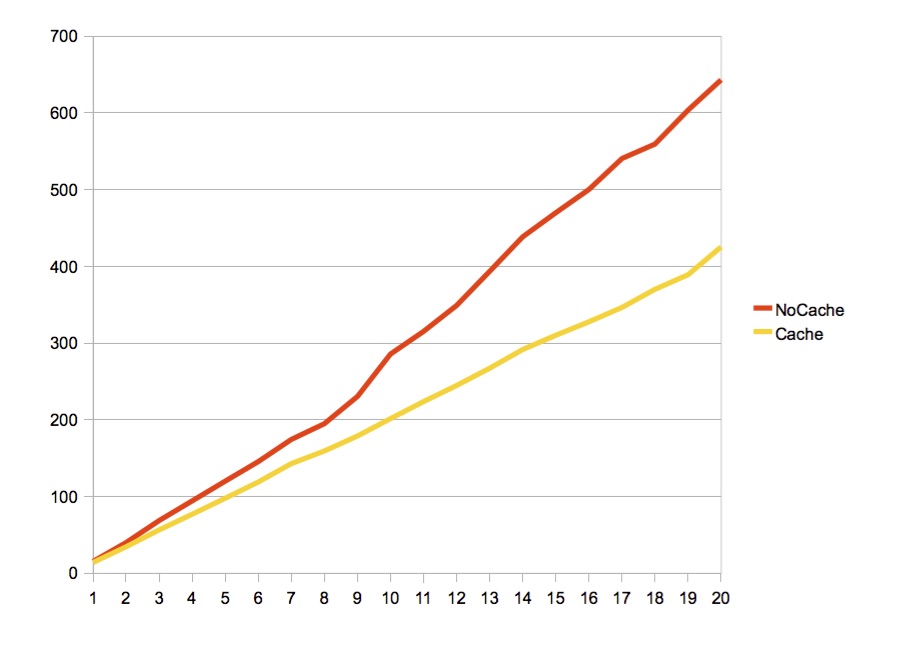 |
5.24 Table locking
At default, the database system allows concurrency access on the same data for any update transaction, since for normal operations, there should be no issues. In case of heavy concurrent updates on a single table, deadlock errors might occur. Also in case of nested update or delete operations within a cursor loop of a stored procedure, undesirable effekts may occur. To avoid this situation, explicit locks can be set up for a table. This synchronizes the concurrency on table level, which should avoid the described effects.
To set a lock on a table, just enter the command
CGCLT > lock table t1; Table t1 locked ok ( 0.000 s ) |
Now the update operation can occur on the table
CGCLT > update 1 set b = 'UPDATED' where a = 4711; 1 tuple updated ok ( 0.000 s ) |
After finishing the update operation, the table is unlocked
CGCLT > unlock table t1; Table t1 unlocked ok ( 0.000 s ) |
Please note, that the table can just be unlocked by the calling database thread. The unlock table operation is idempotent.
For the use of the lock statement in stored procedures, it is recommended to catch any exception during a table is manually locked. In the exception block, another unlock operation should occur to ensure, that the table can be accessed now by other database threads. We give a sample for a procedure, which returns the next available counter value managed by an id table tab_id
@ create procedure nextId(id in string(30)) return long begin var idval long; lock table tab_id; update tab_id set idval=idval + 1 where id = :id return :idval = idval; unlock table tab_id; return :idval; exception when any then unlock table tab_id; end; @ |
Another example, where explicit locking is needed, is illustrated in the following.
The procedure deleteWorker should remove a worker entry from a table worker.
Since there might be employment and fee entries for this worker, the corresponding records also have to be removed.
For this, in the stored procedure a cursor for table employment is created to retrieve all entries for the given worker.
Then another procedure deleteEmployment is called to perform the delete operations on the employment and empfee entities.
Since the outer cursor loop sets already a shared lock on the table employment, the request for an exclusive will fail and
the procedure call will result in a locking timeout.
To avoid this effect, an explicit lock is set for table employment before the cursor loop in entered.
The lock then later is released after the loop is finished but also, if any core operation exception has occured.
drop if exists procedure deleteEmployment;
@
create procedure deleteEmployment(empid in int)
begin
delete from empfee where empid = :empid;
delete from employment where empid = :empid;
end;
@
drop if exists procedure deleteWorker;
@
create procedure deleteWorker(wkid in int)
begin
var empid int;
lock table employment;
cursor empCur as select empid as empid from employment where wkid = :wkid;
while fetch empCur into (:empid)
begin
deleteEmployment(:empid);
end;
close empCur;
unlock table employment;
delete from worker where wkid = :wkid;
exception when core_op
then
unlock table employment;
end;
@
|